![kt cloud [Tech blog]](https://tistory1.daumcdn.net/tistory/4226485/skinSetting/5f51ae7c887a4da787cd295f70f910e5)
[kt cloud Container개발팀 김소미 님]

Kubernetes Control Plane과 친해지기 #1
“Kubernetes”는 Container 생태계를 관리하는 Container Orchestration Tool이라는 것은 익히 들어 보셨을겁니다.
Kubernetes는 Container를 만들고, 없애고, 이동시키며 상태도 감시하는 일을 하는데요.
그렇다면 이 Kubernetes의 주요 Component들이 어떤 것이 있고, 또 어떤 일들을 하고 있는지 파헤치는 시간을 가져보도록 하겠습니다.
Kubernetes Architecture

Kubernetes는 위와 같이 여러 구성 요소들이 모여 하나의 “Cluster”를 이루는 융합체입니다. 크게 전체 클러스터를 관리하는 Control Plane과 실제 컨테이너들이 Pod단위로 실행되는 Worker Node로 구분될 수 있습니다.
오늘 다뤄볼 내용은 이 중에서도 Kubernetes의 중심이라 할 수 있는 Control Plane 영역, 흔히 Master라고 하는 곳을 살펴보고자하는데요. 구성 요소는 크게 “API-Server”, “Controller Manager”, “etcd”, “Scheduler” 4개로 구분 할 수 있습니다.
API-Server
api-server는 Kubernetes의 모든 요청을 받아내며 모든 인증과 인가를 처리하는 관문 역할을 합니다.
api-server는 모든 Component와 Client에서 Cluster의 조회 및 관리에 필요한 Rest API Interface를 제공하고 그 상태는 모두 etcd에 저장합니다.
kubernetes에서는 “kube-api-server” 라는 이름으로 기본 배포됩니다.
- 주요 기능 :
- 인증(Authentication) : Kubernetes API Server는 요청을 보낸 Client를 여러 인증* 플러그인을 가지고 요청 받은 인증서 또는 HTTP 헤더에서 인증 정보를 가지고 인증을 수행합니다.
- 인가(Authorization) : 요청한 작업이 해당 리소스에 대해 수행할 수 있는 권한이 있는지 인가* 플러그인을 통해서 결정합니다.
- Admission Control : Admission Controller Plugin을 사용하며 인증/인가 작업 후 추가적으로 Request 내용에 대한 검증이나 요청 내용을 강제로 변경(mutate)하거나 특정 행동을 제한(validate) 하는 기능입니다. Kubernetes 버전마다 다르지만 기본적으로 Admission Controller들이 등록되어 있으며, 대표적인 예시로는 LimitRange, ResourceQuota, CertificateSigningRequest 등이 있습니다.
| *인증 : x.509 인증서, Static token file, Bootstrap token, ServiceAccount token, openID connect, webhook(webhook 인증서버), proxy auth 등 다양한 인증 방식 선택 *인가 : Node / ABAC / RBAC / Webhook 등 -Node : 실행 예정인 Pod를 기반으로 kubelet이 API 작업을 수행할 수 있도록 권한을 부여하는 특수 목적 인증 모드. (system:nodes) -RBAC(Role-Based-Access-Control) : 사용자의 Role(역할)에 따라 컴퓨팅 또는 네트워크 리소스에 대한 Access를 규제하는 방법. -ABAC(Attribute-based-access-control) : Subject(주체), Object(대상), Action(액션), Attribute(속성) 등을 권한 정책을 미리 json 파일로 만들어 두어 API-server가 시작할 때 밀어 넣음. ABAC은 결합된 속성에 따라 접근 권한이 부여되기 때문에 구체적이고 세분화된 규칙을 수립하는데 유리. -Webhook : LDAP, basic auth 나 bearer token 등 다른 인증 시스템으로 인증을 요청하도록 webhook을 걸어서 API-Server가 인증 받도록 하는 모드. (TokenReview) |
Controller Manager
Controller Manager는 Desired(원하는) 조건에 따라 맞춰 controller loop를 통해 지속적으로 감시하고 api-server에 알려주는 역할을 합니다.
Controller Manager의 설명에 앞서 아래와 같이 용어를 먼저 정리해 보면 좋을 것 같습니다.
- Controller : Controller란 어떤 Object를 감시하는 하나의 Loop 개념입니다. 보통 “controller loop” 또는 “sync loop” 라고 부릅니다.
- Controller Loop : 소스코드로 설명하자면 아래의 간단한 예시와 같이 desired와 current 상태를 체크하여 항상 원하는 상태로 맞추도록(Reconciliation) 반복합니다.
| for { desired := getDesiredState() current := getCurrentState() makeChanges(desired, current) } |
- Controller Binary : 위에서 설명한 “Controller Loop” 개념을 실행하는 Binary를 지칭하는데, 보통 “Controllers”라고 부릅니다.
그렇다면 Kubernetes에서의 Controller Manager란 뭘까요?
바로 위에서 설명한 “Controller”의 역할을 하는 “Controller Binary”가 Kubernetes에서 불려지는 명칭입니다.
Kubernetes의 기본 Built-in Controller Binary Daemon의 이름은 “kube-controller-manager”이며 Kubernetes 설치 시 확인할 수 있습니다.
- 주요 Controller :
- Node Controller: Node가 다운될 때 감지하고 대응합니다.
- Job Controller: 일회성 작업을 나타내는 Job을 감시한 다음, 해당 작업을 완료할 때까지 실행하는 Pod를 생성합니다.
- Replication Controller: Desired Pod 개수 유지하는 역할을 합니다.
- EndpointSlice Controller: Service와 Pod간 링크 제공을 위해 EndpointSlice 개체를 채웁니다.
- ServiceAccount Controller: 새 네임스페이스에 대한 기본 ServiceAccount를 만듭니다.
+ Custom Resource
여기서 추가적으로 Custom Controller도 알아볼까요?
Kubernetes를 사용하다 보면 “CRD”와 “Operator”라는 용어를 많이 들어보셨을텐데요.
용어 정리를 먼저 시작해보도록 하겠습니다.
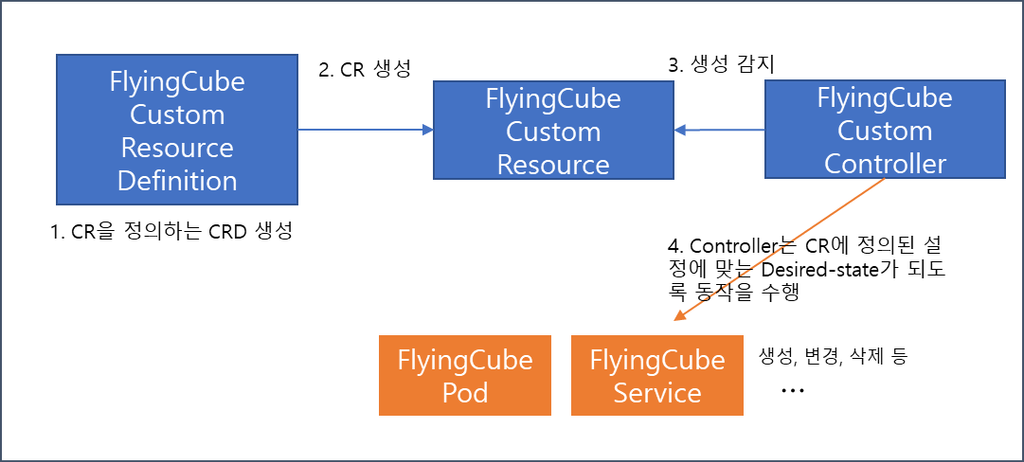
- CR(Custom Resource) : Kubenetes에서 Application을 개발하다보면 나만의 환경에 맞는 추가적인 기능이 필요할 수 있습니다. 이때 사용자는 Kubernetes Object를 직접 정의하여 할 수 있는데, 이를 Custom Resource라고 합니다. 이때 따로 Kubernetes 소스코드를 수정하는 것이 아닌, api-server에 추가 등록만 하면 되도록 자유로운 API Extension(확장) Interface를 제공합니다.
- CRD(Custom Resource Definition) : Custom Resource를 생성하기 위한 api-server에 등록할 API의 Endpoint 정의서입니다.
- Operator : CRD와 함께 구현되는 Custom Controller이며 좀 더 복잡한 상태의 Application 인스턴스를 생성하고 관리할 수 있습니다. Operator는 Kubernetes 원칙, 특히 “Controller Loop”를 따라야 합니다.
이 3가지가 만족된다면 여러분도 나만의 Kubernetes Resource를 만들어 볼 수 있습니다. 간단하게 한번 만들어볼까요?
| # CRD 간단 예제 apiVersion: "apiextensions.k8s.io/v1beta1" kind: "CustomResourceDefinition" metadata: name: "flyingcube" spec: group: "ktcloud" version: "v1" scope: "Namespaced" names: plural: "flyingcube" singular: "flyingcube" kind: "Flyingcube" validation: openAPIV3Schema: required: ["spec"] properties: spec: required: ["developer"] properties: developer: type: "string" minimum: 1 --- # CR 간단 예제 apiVersion: "ktcloud/v1" kind: "Flyingcube" metadata: name: "my-custom-resource" spec: developer: "i am a developer" |
(출처: https://kubernetes.io/docs/tasks/extend-kubernetes/custom-resources/custom-resource-definitions/)
여기까지 따라하셨다면 이제 “Flyingcube”라는 Kind를 가진 Kubernetes Resource를 생성할 수 있습니다!
apiVersion은 “ktcloud/v1”이며, 필요한 spec은 “developer” 라는 필드를 가졌네요.
위와 같이 생성한 “Flyingcube” Resource는 api-server를 통해 etcd에 저장되지만, pod나 deployment와 같이 기존 Kubernetes Resource와는 다르게 특별한 동작을 하지 않습니다.
이를 움직이게 하려면 어떻게 해야 할까요? 바로 Custom Controller인 Operator를 개발하여 내가 원하는 동작을 하도록 알려줘야 합니다.
물론 pod, deployment, job 등 기본 Kubernetes Resource는 Controller Manager가 미리 개발되어 있어서 편히 사용할 수 있었습니다.
![]()
Custom Resource에 대한 Flow를 그려보면 아래와 같이 간단히 표현해 볼 수 있습니다.
Scheduler
Scheduler는 kubelet이 Pod(Container)를 실행 할 수 있도록 특정 Node에 적합한지 확인하고 배정해주는 역할을 합니다.
Kubernetes 기본 Scheduler 이름은 “kube-scheduler”으로 제공되며, 추가적으로 필요에 따라 자체 Scheduling Component를 만들고 대신 사용할 수 있도록 설계되어 있습니다.
Scheduler는 아래와 같이 Filter - Score - Bind 라는 3단계 과정을 통해 적절한 Node를 찾게 됩니다.

Node Filter 조건
|
ETCD
Kubernetes의 모든 Resource들의 설정 및 상태(State)를 Snapshot처럼 저장하는 key:value 저장소입니다.
- 특징 :
- etcd는 kubernetes의 Node가 몇개인지, 어떤 Pod가 어떤 노드에서 동작하는지, Node의 상태 및 어떤 서비스가 Deploy 되어있는지 등의 모든 데이터가 etcd에 저장됩니다.
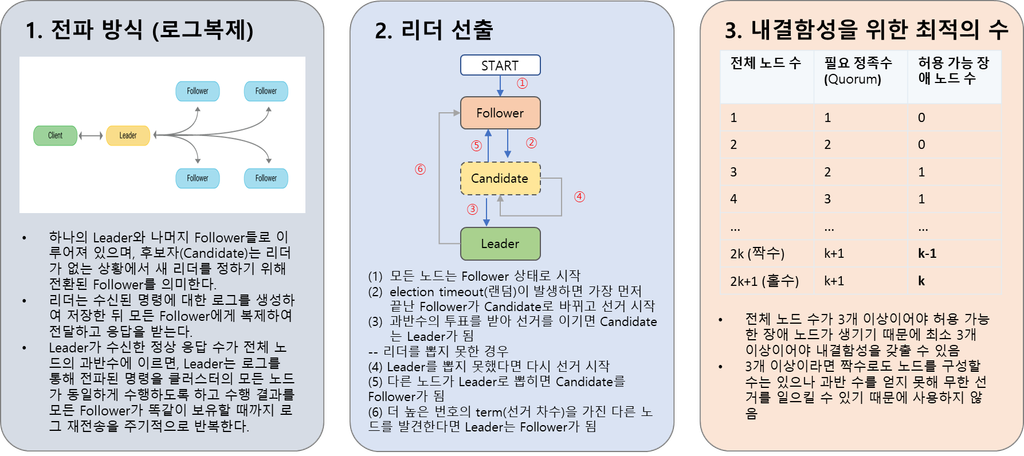
- etcd는 RSM(Replicated state machine)방식으로 분산 컴퓨팅 환경에서 서버가 몇 개 다운 되어도 정상 동작하도록(내결함성) 동일 데이터를 여러 서버에 계속하여 복제합니다.
- Consensus Module이 데이터를 여러 서버에 복제하고, Log append로 데이터를 순차적으로 처리합니다.
- 또한 etcd는 RSM 방식에서 Consensus를 확보하기 위해 Raft 알고리즘을 사용하기 때문에 홀수 개의 수를 유지하도록 권장됩니다.
+Raft 알고리즘

위의 etcd에 특징에서 볼 수 있듯 etcd에서 중요한 역할을 하는 Raft의 의미를 알아보겠습니다. Raft란 로그(Log)를 모아 만든 Raft(뗏목)이라는 뜻인데요.
만약 etcd에 문제가 발생하는 경우 어떻게 될까요? Kubernetes의 모든 정보는 etcd에 저장되어 있는데, 이에 오류가 생겨 날아간다면 모든 Kubernetes Resource가 사라지게 될 수 있습니다.
따라서 etcd는 여러 대의 etcd 중 Raft 알고리즘을 통해 Leader를 선출하며, Leader의 주도로 지속적으로 데이터를 복제하여 Fault Tolerance(내결함성) 및 High Availability(고가용성)을 가집니다.
Raft 알고리즘의 특징은 아래 3가지로 정리할 수 있습니다.
Flow Sequence Diagram

만약 사용자가 “kubectl”명령어를 통해 “Pod”를 생성하면 Kubernetes 에선 어떤 일이 일어날까요?
앞에서 설명한 Control Plane(api-server, etcd, controller-manager, scheduler)의 특징을 기억하면서, Sequence Diagram을 따라가며 살펴봅시다.
- kubectl create -f pod.yaml
- kubectl를 통해 Pod를 하나 생성하도록 명령어를 입력하면 CLI에서 자동으로 Rest API로 변환하여 api-server로 요청합니다. - save new state
- api-server는 수신한 모든 state data를 etcd에 저장합니다. api-server에게 client는 kubectl이 될수도, contoller manager나 kubelet이 될 수도 있습니다. - check for changes
- controller manager는 api-server를 Watch하여 변경사항이 있는지, 자신이 할일이 있는지 확인합니다. 예시에는 Pod 생성 요청만 들어왔기 때문에 controller manager가 할 일이 없겠네요. - watch for unassigned podswatch for unassigned pods
- scheduler 또한 Pod 배치 요청이 있는지 수시로 Watch하여 확인합니다. - notify about pod nodename=””
- api-server는 scheduler에게 Pod에 대한 정보를 알려줍니다. - assign pod to node
- scheduler는 정해진 규칙에 따라 적합한 Node를 배정하여 api-server에게 알려줍니다. - save new state
- api-server는 상태의 변화 모두 etcd에 저장하는 과정을 거칩니다. 이번에는 scheduling에 대한 data를 저장했을 것입니다. - look for newly assigned pods
- 각 Node 마다 떠 있는 Kubelet 또한 api-server에게 항상 Pod의 생성, 삭제 등의 변화가 있는지 Watch하여 확인합니다. - Bind pod to node
- api-server는 scheduler가 정해준 Node로 Bind 할 수 있도록 pod 정보를 보내줍니다.
10. start container
- kubelet은 요청 받은 spec과 같이 Container Runtime(Docker, Containerd 등)에게 Container 생성을 요청합니다.
11. update pod status
- Container Runtime이 생성된 Pod 내 Container 들이 정상적으로 작동하는지 모니터링하여 상태를 업데이트합니다.
12. save new state
- api-server는 변화된 Pod의 상태를 etcd에 저장하게 되면, 최종적으로 사용자는 Pod의 “Running” 상태를 확인할 수 있습니다.
마무리
지금까지 Kubernetes Control Plane Component들의 역할, 원리에 대해 간단히 알아보았습니다.
Kubernetes를 처음 접하는 분들께는 조금 복잡할 수 있지만, 한번쯤 들어봤던 용어들에 대해 알아 볼 수 있는 기회가 되었으면 좋겠습니다.
참고/출처
'Tech story > Container' 카테고리의 다른 글
| Kubernetes 버전 업그레이드 따라하기(v1.27 to v1.28) (0) | 2024.10.29 |
|---|---|
| eBPF 기반의 강력한 쿠버네티스 네트워킹: Cilium CNI 소개 (1) | 2024.10.24 |
| Spring Rest Docs로 REST API 문서 자동화 (3) | 2024.10.24 |
| 알아보기 1. Container Basic (1) | 2024.10.24 |
| Kubernetes 오픈소스 생태계 탐구: #1. Prometheus와 함께하는 Kubernetes 모니터링 (3) | 2024.10.24 |