![kt cloud [Tech blog]](https://tistory1.daumcdn.net/tistory/4226485/skinSetting/5f51ae7c887a4da787cd295f70f910e5)
[ kt cloud AI플랫폼팀 최지우 님 ]
개요
AI가 고도화되며 대규모 언어 모델(LLM)의 응답 품질과 정확도는 중요한 이슈로 떠오르고 있습니다. 그러나 LLM은 훈련 데이터에 포함된 정보만을 기반으로 작동하기 때문에, 최신 데이터나 특정 도메인에 특화된 정보 제공에는 한계가 있습니다. 이를 해결하기 위한 기술로 RAG(Retrieval-Augmented Generation)와 Vector DB가 주목받고 있습니다. 이 글에서는 RAG의 원리와 Vector DB가 어떻게 AI 모델의 응답 정밀도를 높이는지, 그리고 이를 활용해 실제 애플리케이션을 개념적으로 구성하는 방법을 다룹니다.
1. RAG와 Vector Database란 무엇인가?
RAG를 설명하기에 앞서 Vector DB에 대해 이해하는 것이 좋습니다.
Vector Database란?
Vector DB는 데이터를 벡터(다차원 공간의 점) 형식으로 저장하고, 이를 기반으로 유사한 데이터를 빠르게 검색할 수 있는 데이터베이스입니다. 전통적인 관계형 데이터베이스가 정형 데이터를 다루는 데 초점을 맞춘 반면, 벡터 데이터베이스는 비정형 데이터(텍스트, 이미지, 오디오 등)를 효율적으로 처리하는 데 최적화되어 있습니다.
왜 벡터인가?
텍스트나 이미지와 같은 비정형 데이터는 단순한 숫자나 문자열로 표현하기 어렵습니다. 이를 해결하기 위해 딥러닝 모델(임베딩 모델)은 데이터를 벡터로 변환합니다. 이 벡터는 데이터의 의미적 특성을 다차원 공간에서 나타내며, 유사한 데이터는 공간적으로 가까운 위치에 매핑됩니다.
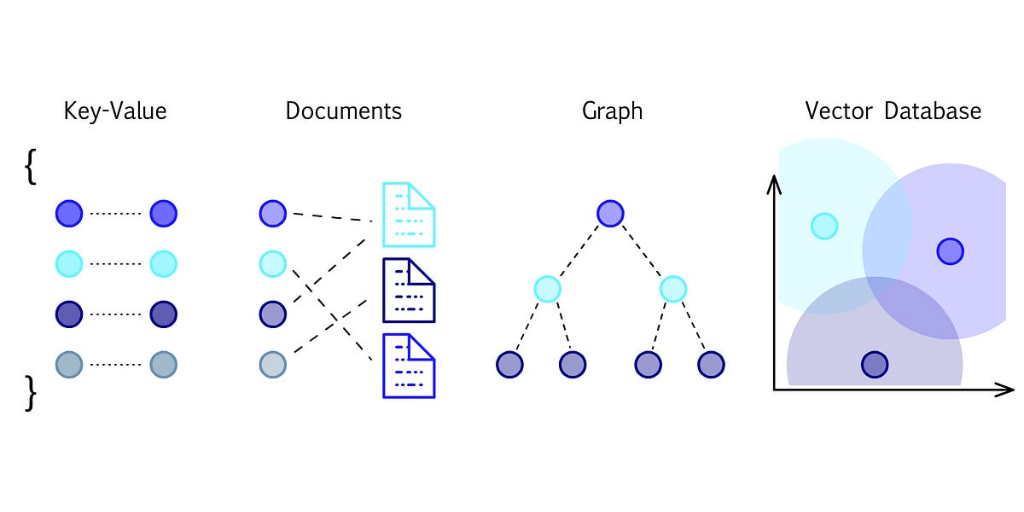
Vector DB는 입력된 벡터와 가장 가까운(유사한) 벡터를 빠르게 검색할 수 있는 기능을 제공합니다. Facebook의 Faiss나 Spotify의 Annoy와 같은 인덱싱 알고리즘이 짧은 시간 내에 유사도를 계산할 수 있도록 도와주는 예시 중 하나입니다.
현대 AI 애플리케이션에서는 단순히 데이터를 저장하고 조회하는 것만으로는 부족합니다. 데이터를 벡터화하고, 의미적으로 유사한 데이터를 검색하는 과정은 AI 서비스의 성능과 품질을 크게 향상시킵니다. 이러한 이유로, Vector DB는 AI 기반 시스템의 필수 구성 요소로 자리 잡고 있습니다.
RAG (Retrieval-Augmented Generation)
RAG는 대규모 언어 모델(LLM)의 한계를 보완하기 위해 검색 기능을 결합한 아키텍처입니다. 간단히 말해, LLM이 답변을 생성하기 전에 관련 데이터를 외부에서 검색해와 이를 활용하는 방식입니다.
RAG는 사용자의 질문(쿼리)이 들어오면, 먼저 쿼리를 벡터화한 후 외부 데이터베이스나 문서 저장소에서 관련 정보를 검색합니다. 이 과정에서 Vector DB를 활용하여 입력 쿼리와 유사한 문서를 효율적으로 찾을 수 있습니다. 그리고 검색된 정보를 기반으로 LLM이 최종 응답을 생성합니다. 검색된 문서들은 LLM의 입력으로 제공되어, 모델이 보다 구체적이고 신뢰할 수 있는 답변을 생성할 수 있도록 돕습니다.
2. RAG 개념 구현해보기
이번에는 Faiss를 이용해 RAG의 기본 개념을 간단하게 구현해보겠습니다. Faiss(Facebook AI Similarity Search)는 Facebook AI에서 개발한 효율적인 벡터 검색 및 클러스터링 라이브러리입니다. 고차원 벡터 간의 유사성을 효율적으로 계산하여 대규모 데이터셋에서도 빠른 검색이 가능합니다. 또한 GPU 가속을 활용해 벡터화 작업과 검색 속도를 크게 향상시키며, L2 거리, 코사인 유사도 등 다양한 거리 계산 방식으로 벡터 간 관계를 분석합니다.
다만 Faiss는 DB의 기능을 가지고 있지는 않으며, 다른 Vector DB에 비해 탐색 속도가 빠른 편은 아닙니다. 그러나 이번에는 RAG의 개념을 구현하는 것이 목적이기 때문에 사용이 간편한 Faiss를 선택했습니다.
개발 환경 및 아키텍처
- kt cloud AI SERV 컨테이너
- 12core 96GB 1GPU(A100 80GB)
- NGC 23.07 - PyTorch 2.1 / CUDA 12.1 / Python 3.10

먼저 Vector DB에 저장해놓을 데이터가 필요합니다. LLM 기준으로는 텍스트 문서가 포함되며, 문서는 Embedding Model을 통해 벡터화되어 DB에 저장됩니다.
사용자가 쿼리(1. Prompt Request)를 통해 응답을 요청하면 어플리케이션은 VectorDB에서 Input Data와 연관이 있는 데이터를 검색(2. Semantic Search)합니다. VectorDB에서 3. 연관 데이터를 반환하면 어플리케이션은 4. 검색된 텍스트를 결합하여 LLM에 전달하고, LLM이 5. 컨텍스트 생성을 하여 사용자에게 6. Reponse 를 반환합니다.
각 과정에 대해 코드를 포함하여 차근차근 설명해보겠습니다.
0. 필수 라이브러리 설치
먼저 Faiss와 sentence-transformers를 설치합니다. sentence-transformers는 문장을 고차원 벡터로 변환해주는 사전 학습 모델입니다. 이번에는 paraphrase-MiniLM-L6-v2 모델을 사용하여 문서 집합을 임베딩하겠습니다.
pip install -U faiss-gpu
pip install -U sentence-transformers1. 텍스트 벡터화 및 Faiss 인덱스 생성
이 단계에서는 문서(텍스트 데이터)를 벡터화하고 검색 가능한 인덱스를 생성합니다. IndexFlatL2라는 L2 거리(유클리드 거리)를 기반으로 검색하는 단순한 인덱스를 사용하고, index.add를 통해 Faiss 인덱스에 추가합니다.
일반적으로 LLM에서 RAG는 외부 데이터나 문서에서 추출한 정보를 기반으로 응답을 생성합니다. 다만 이번 예제에서는 간단한 개념 구현을 위해 문서 대신 몇 가지 문장만을 사용하여 RAG의 동작 원리를 살펴보겠습니다.
texts 리스트에 kt cloud에 대한 정보를 포함한 다섯 개의 문장을 저장해 놓았습니다. 다섯 개의 문장 중 kt cloud와 연관된 문장은 두 문장입니다.
- kt cloud is Korea's number one Cloud Service Provider.
- kt cloud provides AI services such as AI SERV and AI Train.
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
texts = [
"Faiss is a library for efficient similarity search.",
"Hugging Face provides pre-trained models.",
"RAG helps in augmenting generation with retrieval.",
"kt cloud is Korea's number one Cloud Service Provider.",
"kt cloud provides AI services such as AI SERV and AI Train."
]
embeddings = model.encode(texts)
dim = embeddings.shape[1]
index = faiss.IndexFlatL2(dim)
index.add(np.array(embeddings).astype(np.float32))
print(f"Total vectors in Faiss index: {index.ntotal}")2. Faiss를 이용한 벡터 검색
저장된 Index에서 주어진 질문(query)과 가장 유사한 문서 2개를 검색합니다. query_embedding에서 검색어를 벡터로 변환하며, index.search를 통해 변환된 벡터를 FAISS 인덱스에서 검색하여 결과를 반환합니다.
search 함수에서 반환하는 값의 정보는 다음과 같습니다.
- D: 검색된 벡터와 질의 벡터 간의 거리 (작을수록 유사도 높음)
- I: 검색된 벡터들의 Index
query = "Do you know kt cloud?"
query_embedding = model.encode([query])
k = 2
D, I = index.search(np.array(query_embedding).astype(np.float32), k)
print(f"Top {k} similar documents:")
for i in I[0]:
print(texts[i])3. LLM 모델 로드
이제 검색된 문서를 바탕으로 HuggingFace의 LLM 모델을 사용하여 응답을 생성합니다. 여기서는 Llama3-8B-Instruct 모델을 사용하여 문장을 생성해보도록 하겠습니다.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "meta-llama/Meta-Llama-3-8B-Instruct"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)4. 검색된 문서들을 결합하여 컨텍스트 생성
검색 결과의 인덱스(I[0])를 사용해 원본 문서(texts)에서 해당 문장을 가져옵니다. 그리고 input_text에 질문과 문맥을 결합해 LLM에 입력할 형식으로 정리합니다.
context = " ".join([texts[i] for i in I[0]]) # 검색된 문서들 결합
input_text = f"Question: {query}\nContext: {context}\nAnswer:"
# 5. 입력 데이터를 GPU로 이동
input_ids = tokenizer.encode(input_text, return_tensors="pt", padding=True, truncation=True).to(device)5. 텍스트 생성
마지막으로 결과값을 출력합니다.
with torch.no_grad():
output = model.generate(input_ids, max_length=150, num_return_sequences=1, no_repeat_ngram_size=2)
# 7. 생성된 텍스트 디코딩
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
# 8. 결과 출력
print(f"Generated Response: {generated_text}")
응답을 확인해보면 저장되어 있는 5개의 문장 중 질문(Do you know kt cloud?)과 제일 연관성 있는 2개의 문장(Context)이 선택되었으며, 그 문장을 기반으로 답변 문장(Answer)이 생성되었습니다.
답변에서 AI Serv와 AI Train에 대해 설명하는 것으로 보아 RAG가 정상적으로 동작한 것 같습니다.
Generated Response: Question: Do you know kt cloud?
Context: KT Cloud is Korea's number one Cloud Service Provider.
kt cloud provides AI services such as AI SERV and AI Train.
Answer: Yes, I'm familiar with kt Cloud. They offer a range of cloud services,
including infrastructure as a service (IaaS), platform as service(PaaS) and software as services (SaaS).
Their AI-related services include AI Serv, which is a platform that provides various AI capabilities
such AI model training, model management, and model deployment, as well as data management and analytics.
Another service is AI train, a cloud-based AI training platform.
These services are designed to support businesses in developing and deploying AI solutions.
위의 모든 과정을 하나로 통합한 코드는 다음과 같습니다. 이 파이썬 스크립트 하나로 texts 리스트와 query를 변경하여 바로 테스트해보세요!
from sentence_transformers import SentenceTransformer
import faiss
import torch
import numpy as np
from transformers import AutoModelForCausalLM, AutoTokenizer
# 1. Faiss 인덱스 구축
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
texts = [
"Faiss is a library for efficient similarity search.",
"Hugging Face provides pre-trained models.",
"RAG helps in augmenting generation with retrieval.",
"kt cloud is Korea's number one Cloud Service Provider.",
"kt cloud provides AI services such as AI SERV and AI Train."
]
embeddings = model.encode(texts)
dim = embeddings.shape[1]
index = faiss.IndexFlatL2(dim)
index.add(np.array(embeddings).astype(np.float32))
# 2. Faiss를 사용한 검색
query = "Do you know KT Cloud?"
query_embedding = model.encode([query])
k = 2
D, I = index.search(np.array(query_embedding).astype(np.float32), k)
# 3. llama3 8B 모델을 이용한 추론
model_name = "meta-llama/Meta-Llama-3-8B-Instruct"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# 4. 검색된 문서들을 결합하여 컨텍스트 생성
context = " ".join([texts[i] for i in I[0]]) # 검색된 문서들 결합
input_text = f"Question: {query}\nContext: {context}\nAnswer:"
input_ids = tokenizer.encode(input_text, return_tensors="pt", padding=True, truncation=True).to(device)
# 5. 텍스트 생성
with torch.no_grad():
output = model.generate(input_ids, max_length=150, num_return_sequences=1, no_repeat_ngram_size=2)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(f"Generated Response: {generated_text}")결론
이 글에서 다룬 예제를 통해, Faiss와 Sentence Transformers를 사용해 문장을 벡터화하고, RAG 아키텍처를 구현하여 LLM이 검색된 데이터를 기반으로 더 정교한 응답을 생성하는 과정을 확인했습니다.
AI 응답의 정밀도를 더욱 높이기 위해 RAG와 Vector Database의 활용은 이제 선택이 아닌 필수가 되어가고 있습니다. LLM을 특정 도메인에 특화된 LLM을 활용하려는 조직의 경우에는 더욱이 Vector DB와 RAG는 기초적인 핵심 기술로 간주되어야 합니다. 하지만 RAG와 Vector DB는 아직 기술적으로 성숙 단계에 이르지 않은 분야입니다. Vector DB로는 Vespa, Chroma, Qdrant 등이 있지만, 현재로서는 기술적으로 두드러지게 앞서가는 솔루션은 없다고 볼 수 있습니다. RAG 기술을 성공적으로 적용하기 위해서는 각 솔루션의 특성과 성능을 깊이 있게 분석하고, 다양한 Vector DB와 RAG 구현 방안을 비교하는 과정이 필수적입니다.

다양한 Vector DB에 대한 비교 정보는 'Picking a vector database: a comparison and guide for 2023'를 확인해보시기 바랍니다.
[관련/출처]
| FAISS Git Repository Meta Llama3-8B Repository |
'Tech Story > AI Cloud' 카테고리의 다른 글
| [Performance Testing] kt cloud AI : 가상화 환경별 GPU 기반 AI 워크로드 성능 비교 (0) | 2025.04.14 |
|---|---|
| [kt cloud] GPU 파워의 AI Train 고속열차 타고 AI 학습의 종착역으로 (3) | 2025.02.10 |
| GPU 1,000장 모니터링 하기: NVIDIA DCGM 활용 전략 (13) | 2024.11.07 |
| NPU로 sLM 서빙하기: 새로운 가능성 탐구 (0) | 2024.10.31 |
| AMD MI250 GPU로 vLLM 최적화 하기 (feat. AI SERV) (1) | 2024.10.14 |